What Is RAG (Retrieval-Augmented Generation)? A Complete Guide in One Article
RAG = retrieval technique + LLM prompt. For example, we ask a question (answer) to LLM, RAG retrieves relevant information from various data sources and injects the retrieved information and the question (answer) into the LLM hints, and LLM gives the answer at last.
Context
Retrieval Augmented Generation (RAG), or RAG for short , has become the hottest LLM application program at present.
It is not difficult to understand that it is to retrieve relevant information through its own pendant database, and then merge it into a prompt template to generate a nice answer for the large language model.
Experiencing the wave of large language model at the beginning of 23 years, we must have a certain understanding of the capabilities of the large language model, but when we apply the large language model to the actual business scenarios will find that the general basic large language model basically can not meet our actual business needs, mainly due to the following reasons:
-
Limitations of Knowledge
The knowledge of the model itself is completely derived from its training data, and the training set of the existing mainstream large language model (ChatGPT, Wenxin Yiyin, Tongyi Thousand Questions...) is basically constructed on the network of public data, for some real-time, non-public or offline data can not be obtained, and there is no way to have the knowledge of this part.
-
The problem of illusion
The underlying principle of all AI models is based on mathematical probability, and its model output is essentially a series of numerical operations, and the large language model is no exception, so it sometimes talks nonsense in a serious way, especially in the scenario that the large language model itself does not have knowledge of a certain aspect or is not good at it. And this illusion problem is more difficult to distinguish, because it requires the user to have the appropriate domain knowledge themselves.
-
Data Security
For enterprises, data security is crucial, and no enterprise is willing to take the risk of data leakage by uploading its own private domain data to a third-party platform for training. This also leads to a trade-off between data security and effectiveness for applications that rely solely on the capabilities of the Generalized Large Model.
RAG is an effective solution to the above problems.
What is RAG?
RAG (Retrieval Augmented Generation) provides a promising solution for generative models to interact with the outside world.
The main role of RAG is similar to that of a search engine, finding the most relevant knowledge for a user's question or the history of a relevant conversation and combining it with the original question (query) to create an information-rich prompt that guides the model to generate accurate output. It essentially applies the principles of In-Context Learning.
To put it directly:
RAG (Retrieval Augmented Generation) = Retrieval Techniques + LLM Prompts
Characteristics of RAG
In terms of how RAG works, it has the following key features:
-
RAG relies on large language models to enhance information retrieval and output, and is limited in its capabilities when used alone.
-
RAG can seamlessly integrate with external data and better address the knowledge shortcomings of general-purpose large language model in vertical and specialized domains.
-
In general, the private database to which RAG is docked does not participate in the training of the large language model dataset, which can improve model performance while better ensuring data privacy and security.
-
The same RAG, the effect of the display is not uniform, largely affected by model performance, external data quality, AI algorithms, retrieval systems and other aspects.
What is the relationship between RAG and large language model?
RAG and large language model relationship:
-
RAG is both a more popular application development architecture for the Large Language Model (LLM) and an extension of its application in vertical domains.
-
It can expand on the powerful features of LLM by accessing domain-specific databases or internal knowledge bases to make up for the shortcomings of general-purpose models in vertical domain knowledge.
-
On the basis of LLM, RAG can better solve the problem of data source through data inner loop.
-
While enhancing the search and generation functions, it can reduce the concerns of industry users about data privacy and security. This also drives it to become an indispensable technical component for all kinds of large language model landing projects.
-
The utilization of RAG can effectively reduce the occurrence of model illusion and further enhance the performance of large model search and generation.
Because of the relatively low training cost, RAG has now been expanded to scenarios such as enterprise information base construction, AI document Q&A, business training, scientific research, etc., which, paired with the AI agent, greatly accelerates the commercialization of large language model.
In order to improve the degree of intelligence and application value of RAG, people even introduced Self-RAG (i.e., self-reflective retrieval enhancement generation method) on the basis of the original retrieval enhancement generation system to further improve the retrieval efficiency and the quality of large language model generation. This is considered a major upgrade and evolution of RAG.
Development stages of RAG
The concept of RAG was introduced in 2020, for the first time combining a pre-trained retriever with a pre-trained seq2seq model with end-to-end fine-tuning. It really took off after 2022, especially with the introduction of ChatGPT, when NLP moved into the era of large language model.
Many people don't realize that RAG has been researching pre-training and SFT since its inception, and RAG for inferential truncation only started to blow up after the LLM era. Because of the high training cost of high-performance large models, academics and industrial-level attempts have been made to enhance model generation by adding RAG modules to the inference phase and integrating external knowledge in a cost-effective way.The scope of RAG retrieval has also been gradually liberalized, with early RAGs focusing on open-source, unstructured knowledge; as the scope of retrieval expands, high-quality data as a source of knowledge has gradually been mitigating the LLM large model's problems of erroneous knowledge and illusions. Recently, there have also been a lot of research on knowledge graphs, self-retrieval and other directions to explore the integration of interdisciplinary and LLM.

Inception and Development of RAG
RAG originated in 2020. It improves the interpretability and modularity of the model by combining pre-trained retrievers and generators to capture knowledge.
Development of RAG in the era of large-scale language modeling: with the rise of large-scale language modeling, RAG technology became a key tool to enhance the usefulness of chatbots and LLM.
Evolution of RAG technology: RAG provides more efficient solutions for complex knowledge-intensive tasks in large models by optimizing key parts such as retrievers and generators
As can be seen from Fig. 1, the enhancement phase of RAG can be in three stages: pre-training pre-training, Fine-tuning fine-tuning, and Inference; and from the augmented data sources, which include three pathways: unstructured data, structured data, and LLM-generated content.
In academia and industry, there is a general consensus on the definition of RAG as follows:
-
Retrieval phase: retrieve relevant documents based on the problem using the coding model.
-
Generation phase: the retrieved context is used as a condition for the system to generate text.
Research Paradigms of RAG
The RAG research paradigm continues to develop and evolve. The thesis its divided into three categories: primary RAG, advanced RAG and modular RAG .
From the development history of RAG, three stages can be summarized Naive RAG, Advanced RAG, Modular RAG.Personally, I believe that the academic classification, for the purpose of research and induction, will be summarized and presented in the past methods. As we have the spirit of innovation, we should practice more in business and go beyond in innovation.

Elementary RAG is primarily concerned with the "search-read" process. Advanced RAG uses more sophisticated data processing, optimizes knowledge base indexing, and introduces multiple or iterative searches. As exploration progresses, RAG integrates other techniques such as fine-tuning, leading to the emergence of a modular RAG paradigm that enriches the RAG process with new modules and provides more flexibility.
Naive RAG
The classic RAG process, also known as Naive RAG, consists of three basic steps:
1. Indexing - Split the document library into shorter chunks and construct a vector index with an encoder.
2. Retrieval - Retrieve relevant document fragments based on the similarity between questions and chunks. 3.
3. Generation - Generate the answer to the question in terms of the retrieved context.
Advanced RAG (Advanced RAG)
Naive RAG has multiple challenges in terms of retrieval quality, response generation quality and enhancement process.Advanced RAG paradigm was then proposed with additional processing in terms of data indexing, pre-retrieval and post-retrieval. Text consistency, accuracy, and retrieval efficiency are enhanced through finer-grained data cleansing, designing document structure, and adding metadata. In the pre-retrieval phase, semantic differences between questions and document blocks can be aligned using question rewriting, routing and expansion. In the post-retrieval stage, the "Lost in the Middle" phenomenon can be avoided by reordering the retrieved document library. Or the window length can be shortened by context filtering and compression.
Modular RAG
With the further development and evolution of RAG technology, the new technology breaks through the traditional Naive RAG search - generation framework, based on which we propose the concept of modular RAG. Structurally it is more free and flexible, introducing more specific functional modules, such as query search engine, fusion of multiple answers. Technically, it integrates retrieval with fine-tuning and reinforcement learning. Processes are also designed and orchestrated between RAG modules, and a variety of RAG models have emerged. However, Modular RAG did not appear suddenly, and there is a relationship of inheritance and development between the three paradigms.Advanced RAG is a special case form of Modular RAG, while Naive RAG is a special case of Advanced RAG.
The five basic processes of RAG
As shown in the figure below RAG can be divided into five basic processes: preparation of knowledge documents; embedding model embedding model; vector database; query retrieval and production of answers. Each of them is described in detail below:
1. Preparation of knowledge documents
When building an efficient RAG system, the first step is to prepare the knowledge documents. In a realistic scenario, the knowledge sources we face may include a variety of formats, such as Word documents, TXT files, CSV data sheets, Excel tables, and even PDF files, images and videos. Therefore, the first step requires the use of specialized document loaders (e.g., PDF extractors) or multimodal models (e.g., OCR techniques) to convert these rich knowledge sources into plain text data that can be understood by large language models. For example, when processing PDF documents, a PDF extractor can be used to extract the textual content; for images and videos, OCR technology can recognize and convert the textual information in them. In addition, given that the document may be too long, we also need to perform a key step: document slicing. We need to split long documents into multiple text blocks in order to process and retrieve information more efficiently. This not only helps reduce the burden on the model, but also improves the accuracy of information retrieval. We will discuss document slicing and the logic behind it in detail later.
2. Embedding Model
The core task of the embedding model is to convert text into vector form. While the everyday language we use is full of ambiguities and auxiliary words that are not useful for expressing the meaning of the words, vector representations are denser, more precise, and able to capture the context and core meaning of a sentence. This transformation allows us to recognize semantically similar sentences by simply calculating the differences between vectors.
For example, if we want to compare "An apple is a fruit" and "A banana is yellow", the embedding model can convert these sentences into vectors, and then determine their degree of relatedness by calculating the similarity between them. So how to get such an embedding model, as a classic example, we developed by Google Word2Vec (an article to see what is what is Word2vec) model as the basis to explore the training process.
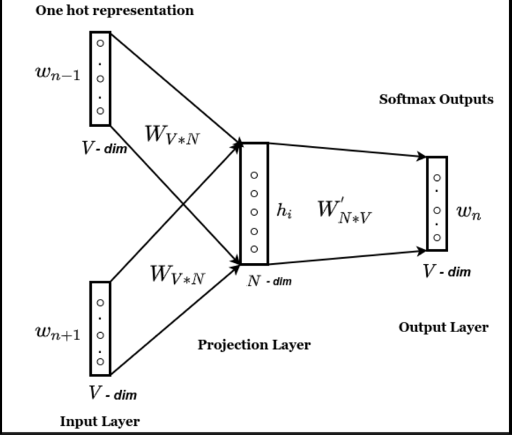
Word2Vec has two training methods, for the sake of simplicity we will explain the CBOW model method shown in the figure above.The core idea of the CBOW model is that given the context of the center word of a sentence (i.e., several words around the word), let the model predict the center word. For example, suppose we have a sentence, "The cat sat on the mat". Using the CBOW model, our goal is to predict the center word "sat". The specific training process is as follows:
-
For the context words "the", "cat", "on", "the", "mat", we first generate their one-hot vectors, which are high-dimensional sparse vectors representing each word in the vocabulary. For example, "the" can be encoded as [1, 0, 0, 0, 0, 0].
-
Next, each one-hot vector is multiplied with a weight matrix W of size V × N (where V is the size of the vocabulary list and N is the dimension of the word vector) to get the word vector for each word. Then, all these word vectors are summed and averaged to obtain a vector e representing the context of the entire sentence (i.e., the 1 × N vector in the projection layer in Fig.)
-
Next, the vector e is multiplied by another output weight matrix W', which is processed by the SoftMax function to obtain an output vector of size 1×V. This vector represents the probability that the model predicts each word to be the center word.
-
Finally, the model's prediction is compared with the actual center word, and the two weight matrices W and W' are constantly updated by this difference. After enough training, the vector e obtained in step 2 can effectively represent the meaning of the whole sentence.
Of course in addition to Word2Vec, there are other advanced embedding models such as BERT and GPT families which capture deeper semantic relationships through more complex network structures. All in all the embedding model is a bridge between the user query and the knowledge base, ensuring the accuracy and relevance of the system's answers.
3. Vector Database
As the name suggests, a vector database is a database system specifically designed to store and retrieve vector data. In a RAG system, all the vectors generated through the embedding model are stored in such a database. Such databases optimize the efficiency of processing and storing large-scale vector data, enabling us to quickly retrieve the most relevant information to a user's query when confronted with massive knowledge vectors.
4. Query Retrieval
After a few more steps of preparation as described above, we are ready to proceed with processing user queries. First, the user's question will be input into the embedding model for vectorization. Then, the system searches the vector database for semantically similar knowledge texts or historical conversation records to the question vector and returns them.
5. Generating Answers
Finally, a prompt template is constructed by combining the user's question and the information retrieved in the previous step, input into the large language model, and wait for the model to output the answer.
12 Optimization Strategies for RAG
The process described in the above section is only the basic RAG process, but there is a great deal of room for optimization in each of its aspects. Here we will intersperse 12 specific optimization strategies from the above 5 links to explain in turn. The methods introduced below are all implemented in the AI development framework langchain and LLamaIndex, the specific operation method can refer to the official document.
1. Data Cleaning
A high-performance RAG system relies on accurate and clean raw knowledge data. On the one hand, in order to ensure the accuracy of the data, we need to optimize the document reader and multimodal model. Especially when dealing with files such as CSV tables, the original structure of the table may be lost by simple text conversion. Therefore, we need to introduce additional mechanisms to recover the table structure in the text, such as using semicolons or other symbols to differentiate the data. On the other hand we also need to do some basic data cleansing of knowledge documents which can include:
-
Basic text cleaning : standardize text formatting, remove special characters and irrelevant information. In addition to duplicate documents or redundant information.
-
Entity resolution : Remove ambiguity from entities and terms to achieve consistent referencing. For example, standardize "LLM", "Large Language Model" and "Big Model" into common terms.
-
Documentation : Rationalize the documentation of different topics - are the different topics in one place or are they spread out in multiple places? If humans can't easily determine which documents they need to consult to answer common questions, neither can retrieval systems.
-
Data augmentation : Use synonyms, paraphrases, and even translations into other languages to increase the diversity of the corpus.
-
User feedback loops : constantly update the database based on feedback from real-world users, marking them as authentic.
-
Time-sensitive data : for frequently updated topics, implement a mechanism to invalidate or update outdated documents.
2. Chunking
In RAG systems, documents need to be split into multiple text chunks before vector embedding. Without considering large model input length constraints and cost issues, the goal is to minimize the noise in the embedded content while maintaining semantic coherence, so as to more efficiently find the part of the document that is most relevant to the user's query. If the chunks are too large, they may contain too much irrelevant information, thus reducing the accuracy of the retrieval. Conversely, chunks that are too small may lose necessary contextual information, resulting in a generated response that lacks coherence or depth. Implementing an appropriate document chunking strategy in a RAG system aims to find this balance and ensure the completeness and relevance of information. In general, the ideal chunk of text should still make sense to a human in the absence of surrounding context, so that it makes sense to the language model as well.
Choice of chunking methods
Fixed-size chunks: this is the simplest and most straightforward method, where we directly set the number of words in a chunk and choose whether or not to repeat content between chunks. Typically, we keep some overlap between chunks to ensure that semantic context is not lost between chunks. Fixed-size chunking is easy to use and doesn't require many computational resources compared to other forms of chunking.
Content chunking
As the name suggests, chunking is done based on the specific content of the document, for example based on punctuation (e.g., periods). Or just use the more advanced sentence chunking functions provided by the NLTK or spaCy libraries.
Recursive chunking
The recommended method in most cases. It recursively breaks down text by repeatedly applying chunking rules. For example, in langchain the chunks are first split by paragraph breaks (`\n\n`). Then, the size of these chunks is checked. If the size does not exceed a certain threshold, the block is retained. For blocks whose size exceeds the threshold, they are segmented again using the single line break (`\n`). And so on, constantly updating smaller chunking rules (e.g., spaces, periods) based on the block size. This approach allows flexibility in resizing blocks. For example, for densely informative parts of the text, finer segmentation may be needed to capture details; while for less informative parts, larger chunks can be used. And its challenge is that fine-grained rules need to be developed to determine when and how to segment the text.
From small to large chunks
Since small chunks and large chunks each have their own advantages, a more straightforward solution is to split the same document in all sizes from large to small, and then store all the chunks of different sizes in a vector database and save the contextual relationships of each chunk for recursive search. However, it can be imagined, because we want to store a large number of duplicate content, the disadvantage of this program is that it requires more storage space.
Specialized structured chunking
Specialized splitters for specific structured content. These chunkers are specially designed to handle these types of documents to ensure that their structure is properly preserved and understood. langchain offers special chunkers for Markdown files, Latex files, and various major code language chunkers.
Choice of chunk size
All of the above methods without exception end up with one parameter - the chunk size, so how do we choose it? First of all, different embedding models have their optimal input sizes. For example, Openai's text-embedding-ada-002 model works better with a block size of 256 or 512. Second, the type of document and the length and complexity of the user query are also important factors in determining the chunk size. When dealing with long articles or books, larger chunks help retain more contextual and thematic coherence; while for social media posts, smaller chunks may be more suitable for capturing the precise semantics of each post. If the user's query is usually short and specific, smaller chunks may be more appropriate; conversely, if the query is more complex, larger chunks may be needed. In real-world scenarios, we may still need to keep experimenting and adjusting. In some tests, chunks of size 128 are often the best choice, and when there is no way to start, we can test from this size as a starting point.
3. Embedding model
We mentioned that embedding models can help us convert text into vectors. Obviously, different embedding models bring different results, for example, the Word2Vec model we discussed before, although powerful, has an important limitation: the word vectors it generates are static. Once the model is trained, the vector representation of each word is fixed, which can lead to problems when dealing with cases of multiple meanings of a word.
For example, "I bought a CD-ROM", where "CD-ROM" refers to a specific round disk, whereas in "CD-ROM Action", "CD-ROM" refers to putting the CD-ROM on the table. In "Operation CD", "CD" refers to eating all the food on the plate, which is a kind of behavior that advocates saving money. The word vectors with completely different semantics are fixed. In contrast, models that introduce a self-attention mechanism, such as BERT, can provide dynamic word sense understanding. This means that it can dynamically adjust word meanings according to the context, making the same word have different vector representations in different contexts. In the previous example, the word "CD-ROM" would have different vectors in two sentences, thus capturing its semantics more accurately.
Some projects embed models to fine-tune them for better understanding of words in specific verticals. However, we do not recommend this approach, because on the one hand, it requires high quality of training data, and on the other hand, it also requires more investment in human and material resources, and the result may not be ideal, which is not worth the loss in the end. In this case, we recommend Hugging Face's embedding model ranking MTEB, which provides a comparison of the performance of various models and helps us make a more informed choice. At the same time, it should be noted that not all embedding models support Chinese, so you should consult the model description when choosing one.
4. Metadata
When storing vector data in a vector database, some databases support storing vectors together with metadata (i.e., non-vectorized data). Adding metadata annotations to vectors is an effective strategy to improve retrieval efficiency, and it plays an important role in processing search results.
For example, date is a common metadata label. It helps us filter based on chronological order. Imagine if we are developing an application that allows users to query their email history. In this case, emails with the most recent date might be more relevant to the user's query. However, from an embedding perspective, we cannot directly determine how similar these emails are to the user's query. By attaching the date of each email as metadata to its embedding, we can prioritize the most recently dated emails in the retrieval process, thus improving the relevance of the search results.
In addition, we can also add things such as chapter or subsection references, key information about the text, subsection titles or keywords as metadata. These metadata not only help to improve the accuracy of knowledge retrieval, but also provide a richer and more precise search experience for end users.
5. Multi-level indexing
In cases where metadata cannot adequately distinguish between different context types, we can consider further attempts at multiple indexing techniques. The core idea of multiple indexing technology is to divide huge data and information requirements by categories and organize them in different levels for more effective management and retrieval. This means that the system does not just rely on a single index, but creates multiple indexes for different data types and query needs. For example, there may be one index that specializes in summary-type questions, another that responds to questions that directly seek a specific answer, and yet another that specializes in questions that require time considerations. This multiple indexing strategy enables the RAG system to select the most appropriate indexes for data retrieval based on the nature and context of the query, thus improving retrieval quality and response time. However, in order to introduce the multiple indexing technique, we also need to incorporate a multilevel routing mechanism as an accompaniment.
The multilevel routing mechanism ensures that each query is efficiently directed to the most appropriate index. Queries are routed to one or more specific indexes based on their characteristics (e.g., complexity, type of information required, etc.). This not only improves processing efficiency, but also optimizes resource allocation and usage, and ensures accurate matching for all types of queries.
For example, for the query "Recommendations for the latest released sci-fi movies", the RAG system may first route it to an index that specializes in current hot topics, and then use indexes focusing on entertainment and movie and TV content to generate relevant recommendations.
Overall, multi-level indexing and routing techniques can further help us to efficiently process large-scale data and extract accurate information, thus improving user experience and overall system performance.
6. Indexing/Querying Algorithms
We can use the index to filter the data, but in the end we still need to retrieve the relevant text vectors from the filtered data. Due to the large volume and complexity of vector data, finding the absolute optimal solution becomes computationally expensive and sometimes even infeasible. Coupled with the fact that large models are not inherently fully deterministic systems, these models pursue semantic similarity in their search - a reasonable match will suffice. From an application perspective, this approach makes sense.
For example, in a recommender system, users are unlikely to notice or care whether every recommended item is an absolute best match; they are more interested in whether the recommendations generally match their interests. Therefore, finding items that are identical to the query vector is usually not the goal, but rather finding items that are "close enough" or "similar", which is called Approximate Nearest Neighbor Search (ANNS). This is called Approximate Nearest Neighbor Search (ANNS). This not only meets the requirements, but also offers great optimization potential for search optimization. In the following, we will introduce some common vector search algorithms so that you can make trade-offs in specific usage scenarios.
Clustering
When we shop online, instead of blindly searching through all the products, we usually choose to enter a specific product category, such as "electronics" or "apparel", and look for our favorite products in a more subdivided category. This can help us greatly narrow the search scope. Along the same lines, clustering algorithms can help us achieve this scope delimitation. For example, we can use the K-mean algorithm to divide the vector into several clusters, when the user query, we only need to find the closest cluster to the query vector, and then search in this cluster. Of course the clustering approach is not guaranteed to be correct, as shown in the following figure, the query is closer to the center of the yellow cluster, but in fact the closest to the query vector, i.e. the most similar points are in the purple category.

There are ways to mitigate this problem, such as increasing the number of clusters and specifying that multiple clusters be searched. However, any approach that improves the quality of the results will inevitably increase the time and resource cost of the search. In fact, there is a trade-off between quality and speed. We need to find an optimal balance between the two, or find a balance that is suitable for a particular application scenario. Different algorithms correspond to different balances.
You can take a look at What is K-mean clustering in one article.
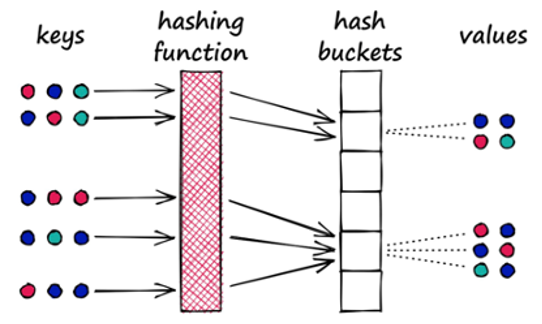
Location Sensitive Hashing
Along the lines of narrowing down the search, location-sensitive hashing algorithms are another strategy to implement. In traditional hashing algorithms, we usually want each input to correspond to a unique output value and try to minimize the duplication of output values. However, in location-sensitive hashing algorithms, our goal is the opposite; we need to increase the probability of collision of output values. Such collisions are the key to grouping, where vectors with the same hash value are assigned to the same group, i.e., the same "bucket". In addition, this hash function needs to fulfill another condition: spatially closer vectors are more likely to be in the same bucket. When searching, you only need to get the hash value of the target vector, find the corresponding bucket, and search within that bucket.
Quantization products
Above we described two ways to improve search speed by sacrificing search quality, but besides search speed, memory overhead is also a huge challenge. In real-world scenarios, each vector often has thousands of dimensions and up to hundreds of millions of data. Each piece of data corresponds to an actual piece of information, so it is not possible to delete the data to reduce the memory overhead, so the only option is to reduce the size of each piece of data itself. There is a method of product quantization that can help us do this. A lossy compression method for images is to combine several pixels around a pixel to reduce the amount of information that needs to be stored. Similarly we can improve on the clustering method by replacing the data points in a cluster with the center of each cluster. Although we lose information about the specific values of the vectors this way, given the degree of correlation between the cluster centroids and the vectors in the clusters, plus the fact that the number of clusters can be continually increased to minimize the loss of information, we can to a large extent retain the information of the original points. And the benefits of doing so are substantial. If we encode these centroids, we can reduce the storage space by storing a vector with a single number. And we record the value of each center vector and its coded value to form a codebook, so that each time we use a vector, we just use its coded value to find the exact value of the corresponding center vector through the codebook, although the vector is no longer the same as it was in the first place, but as mentioned above, it's not a big problem. This process of representing the vector as the center of the cluster it is in is called quantization.

But you may find that the codebook introduces additional overhead. In real scenarios because of the dimension explosion problem, the data distribution is sparser in higher dimensions, so we need more number of clusters to reduce the lost details, like for a 128 dimensional space, we need 2 to the 64th power of the cluster centers, so eventually the memory required for this codebook becomes horrible, even beyond the memory saved by the quantization itself. The solution to this problem is to split the high-dimensional vector into multiple low-dimensional subvectors, and then quantize independently in these low-dimensional subvectors. For example, a 128-dimensional vector is split into eight 16-dimensional subvectors, which are then independently quantized in eight separate subspaces to form their own subcodebook.
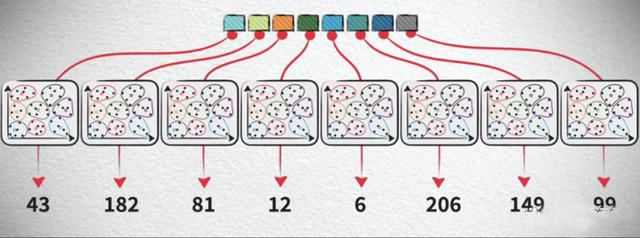
Each 16-dimensional space only needs 256 clusters to get good results, and each sub-codebook will become so small that even the size of the 8 sub-codebooks together will still be small enough that we are actually decomposing the codebook size growth from an exponential model to an additive model. Finally, we can also combine the previous speedup method with the product quantization method of memory reduction to achieve both speed and memory optimization.
Navigating the Small World in Layers
From a customer's perspective, memory overhead may not be the most important consideration. They are more concerned with the end result of the application, which is the speed and quality of answering the user's questions. The Navigating Small Worlds (NSW) algorithm is an implementation that trades memory for speed and quality. The idea is similar to the "six degrees of separation theory" - there are at most six people between you and any stranger, i.e. you can get to know any stranger through at most six people. We can compare people to vector points, and think of the search process as finding one person from another. When querying, we start with a selected starting point A, then find the point B that is adjacent to A and closest to the query vector, navigate to point B, and make similar judgments again, and so on, until we find a point C for which none of its neighboring nodes is closer to the target than it is. Eventually this point C is the most similar vector we are looking for.
7. Query Transformation
In the RAG system, the user's query question is transformed into a vector, which is then matched in a vector database. Not surprisingly, the wording of the query directly affects the search results. If the search results are unsatisfactory, the following methods can be tried to rephrase the question to enhance the recall effect:
Rephrasing in conjunction with historical dialog
In vector space, two questions that appear to be the same to humans do not necessarily have similar vector sizes. We can try this directly by rephrasing the questions using LLM. In addition, during multiple rounds of dialog, a word in a user's question may refer to part of the information in the above text, so the historical information and the user's question can be given to the LLM for rephrasing.
Hypothetical Document Embedding (HyDE)
The core idea of HyDE is to receive a user's question and then let the LLM generate a hypothetical response without external knowledge. This hypothetical reply is then used for vector retrieval along with the original query. The hypothetical response may contain false information, but it contains information and document patterns that the LLM considers relevant and helps to find similar documents in the knowledge base.
Step Back Prompting
If the original query is too complex or the information returned is too extensive, we can choose to generate a "step back" question at a higher level of abstraction that can be used in conjunction with the original question to increase the number of results returned. For example, whereas the original question was "what school did Table went to at a particular time", the fallback question might be about his "educational history". Such higher-level questions may be easier to find answers to.
Multi Query Retrieval (MQR)
The use of LLMs to generate multiple search queries is particularly useful in situations where a question may rely on multiple sub-questions.
Through these methods, the RAG system is able to process and respond to complex user queries more accurately, thus improving overall search efficiency and accuracy.
8. Search Parameters
Finally we have the query question ready to enter the vector database for retrieval. In the specific search process, we can optimize some search parameters according to the specific settings of the vector database, the following are some common settable parameters:
Sparse and dense search weights
Dense search means searching through vectors. However, there may be limitations in some scenarios, where sparse search using raw strings for keyword matching can be attempted. An effective sparse search algorithm is Best Match 25 (BM25), which is based on counting the frequency of words in the input phrases, where frequently occurring words are scored lower and rare words are considered as keywords and will be scored higher . We can combine sparse and dense search to arrive at the final result. Vector databases usually allow to set the proportion of weight of both on the final result score, e.g. 0.6 means that 40% of the score comes from sparse search and 60% from dense search.
Number of results (topK)
The number of search results is another key factor. Sufficient search results ensure that the system covers all aspects of the user's query. When answering multifaceted or complex questions, more results provide rich context and help the RAG system better understand the context and implicit details of the question. However, it is important to note that too many results may lead to information overload, reducing answer accuracy and increasing the system's time and resource costs.
Similarity Measures
Methods for calculating the similarity of two vectors are also an optional parameter. This includes calculating the difference between two vectors using the Euclidean and Jaccard distances, as well as measuring the similarity of angles using the cosine similarity. Typically, cosine similarity is preferred because it is independent of the length of the vectors and only reflects similarity in direction. This allows the model to ignore text length differences and focus on the semantic similarity of the content. It is important to note that not all embedding models support all metrics, as described in the description of the embedding model used.
9. Advanced Search Strategies
Finally we come to the most critical and complex step - how to specifically develop or improve the overall system strategy on top of vector database retrieval. There is enough content in this section to write a separate article. To keep it concise, we will only discuss some commonly used or newly proposed strategies.
Context Compression
We have mentioned that when a document chunk is too large, it may contain too much irrelevant information, and delivering such a whole document may result in more expensive LLM calls and poorer responses. The idea of context compression is to compress the content of a single document according to its context with the help of LLM, or to filter the returned results to a certain extent to return only relevant information.
Sentence Window Search
On the contrary, a document text block that is too small can lead to a lack of context. One solution is window search, the core idea of which is that when a question is asked to match a chunk, the chunks around the chunk are given to the LLM for output as context to increase the LLM's understanding of the context of the document.
Parent Document Search
Not coincidentally, the parent document search is also a very similar solution, the parent document search will first be divided into a larger size of the main document, and then the main document is divided into shorter sub-document level, the user question will be matched with the sub-document, and then the sub-document belongs to the main document and the user's question is sent to the LLM.
Auto Merge
Auto-merge is a complex solution that takes the parent document search one step further. Similarly, we first cut the structure of the document, for example, cut the document in a three-layer tree structure, the block size of the top node is 1024, the block size of the middle layer is 512, and the block size of the leaf node at the bottom layer is 128, and in the retrieval, we only take the leaf nodes and the question to be matched, and when the majority of the leaf nodes under a certain parent node match with the question, then the parent node will be returned as the result.
Multi-vector search
Multi-vector retrieval also converts a knowledge document into multiple vectors to be stored in the database, but the difference is that these vectors not only include chunks of the document in different sizes, but also include a summary of the document, questions that may be asked by the user, and other information that can help in the retrieval process. In the case of a query using multiple vectors, each vector may represent a different aspect of the document, allowing the system to consider the document content more comprehensively and provide more accurate results in answering complex or multifaceted queries. For example, if the query is more relevant to a specific section or summary of the document, the corresponding vector can help improve the retrieval ranking for that section.
Multi-agent Search
Multi-agent retrieval, in short, is the process of selecting some of the 12 optimization strategies we've mentioned and handing them over to an intelligent agent for combined use. For example, using a combination of sub-question querying, multi-level indexing, and multi-vector querying, the sub-question querying agent first breaks down the user question into multiple sub-questions, then the document agent performs multi-vector or multi-indexed retrieval of each word-question, and then the ranking agent summarizes all the retrieved documents before handing them over to the LLM.The advantage of this is that it can complement the strengths of the sub-question querying engine, which for example, when exploring each sub-query, may lack depth, especially in interrelated or relational data. On the contrary, document agent recursive search excels in delving into specific documents and retrieving detailed answers as a way to synthesize multiple approaches to problem solving. It is important to note that there are different structures of multi-agent retrieval on the web, and it has not yet been determined which optimization steps to take in multi-agent retrieval, so we can explore them in the context of our usage scenarios.
Self-RAG
Self-Reflective Search Augmentation is a new RAG framework that differs most from traditional RAG in that it improves quality through retrieval scores (tokens) and reflection scores (tokens). It is divided into three main steps: retrieval, generation, and critique.Self-RAG first uses the retrieval score to evaluate whether a user question needs to be retrieved or not, and if it does, LLM will call an external search module to find the relevant documents. Then, LLM generates answers for each retrieved knowledge block, and then generates reflection scores for each answer to evaluate the relevance of the retrieved documents, and finally, the highly rated documents are given to LLM as the final results.
10. Re-ranking model (Re-ranking)
After completing the optimization steps of semantic search, we are able to retrieve the most semantically similar documents, but I wonder if you have noticed a key question: does the most semantically similar always mean the most relevant? The answer is not necessarily. For example, when a user queries "recommendations for the latest released sci-fi movies", the result may be "historical evolution of sci-fi movies", which is semantically related to sci-fi movies but does not directly respond to the user's query about the latest movies.
Rearrangement models can help alleviate this problem by performing a deeper relevance assessment and ranking of the initial search results to ensure that the final results presented to the user are more closely aligned with the intent of the query. This process is usually implemented by deep learning models, such as the Cohere model. These models take into account additional features such as query intent, multiple semantics of terms, historical user behavior, and contextual information.
For example, for the query "Recommendation of newly released science fiction movies", in the first retrieval phase, the system may return results based on keywords, including historical articles on science fiction movies, introductions to science fiction novels, news about the latest movies, etc. Then, in the re-ranking phase, the model may return results based on the keywords. Then, in the rearrangement phase, the model will analyze these results in depth and rank the most relevant results (e.g., list of the latest released science fiction movies, reviews or recommendations) that best match the user's query intent, while ranking those about the history of science fiction movies or less relevant content at the back. In this way, the rearrangement model can effectively improve the relevance and accuracy of the retrieval results to better satisfy users' needs.
In practice, any system built using RAG should consider trying the rearrangement approach to evaluate whether it can improve system performance.
11. Cue words
The decoder part of a large language model usually predicts the next word based on a given input. This means that the way the cue word or question is designed will directly affect the probability of the model predicting the next word. This also gives us some insights: by changing the form of the cue word, it can be effective in influencing how well the model accepts and answers different types of questions, e.g., modifying the cue word so that the LLM knows what it is doing is very helpful.
In order to reduce the probability of the model generating subjective answers and hallucinations, in general, the prompt words in the RAG system should clearly state that the answer is based on the search results only , and do not add any other information For example, you can set the prompt words such as:
"You are an intelligent customer service agent. Your goal is to provide accurate information and help the questioner solve the problem as much as possible. You should remain friendly, but not overly verbose. Please answer the query based on the contextual information provided, without taking into account prior knowledge."
Of course you can also make the model's answer incorporate some subjectivity or its understanding of the knowledge as well, as appropriate for the scenario. In addition, using a small number of samples (few-shot) approach to include examples of the desired Q&A in the prompt words to guide the LLM on how to utilize the retrieved knowledge is also an effective way to improve the quality of the content generated by the LLM. This approach not only makes the model's answers more accurate, but also improves its usefulness in specific contexts.
12. Large Language Modeling
Finally we come to the last step - LLM generated responses.LLM is the core component for generating responses. Similar to embedded models, LLMs can be chosen according to your needs, such as open vs. proprietary models, inference cost, context length, etc. In addition, some LLM development frameworks can be used to build a RAG system, e.g., LlamaIndex or LangChain, both of which have good debugging tools that allow us to define callback functions, see which contexts are used, check which document the retrieved results come from, etc.
Summarize
This article introduces what is RAG, RAG features and development stages, and then talked about the RAG process including 12 optimization strategies, the front-end part of the reading for the general public, the back part of the professionalism is relatively strong, suitable for technical practitioners to read.