A Complete Guide to LangChain: A Framework for Large Language Model Applications
This article is mainly aimed at technical development readers and introduces the LangChain framework, which can combine large language models with other computational or knowledge sources to achieve more powerful applications. Then, the key concepts of LangChain are explained in detail, and some case attempts based on the framework are made to help readers more easily understand how LangChain works.
Introduction
Recently, large-scale language models (LLMs) such as the GPT family of models have led a technological revolution in the field of artificial intelligence. Developers are making various attempts to utilize these LLMs, and while many interesting applications have been produced, it is often difficult to build powerful and practical applications using these LLMs alone.
LangChain enables more powerful AI applications by combining large language models with other knowledge bases and computational logic. In short, I understand that LangChain can be regarded as an open-source version of the GPT plugin, which provides a rich set of tools for large language models that can quickly enhance the model's capabilities based on the open-source model.
Here, I summarize what I have learned recently about LangChain, and welcome all students to come and exchange ideas.LangChain makes the use of language technology more active and diversified, and it is expected to play an important role in the field of artificial intelligence and drive the change in our work efficiency. We are on the eve of the explosion of artificial intelligence, and actively embracing new technologies will bring a brand new experience.
LangChain Key Concepts and Examples
LangChain provides a series of tools to help us better use the Large Language Model (LLM). There are 6 different types of tools:
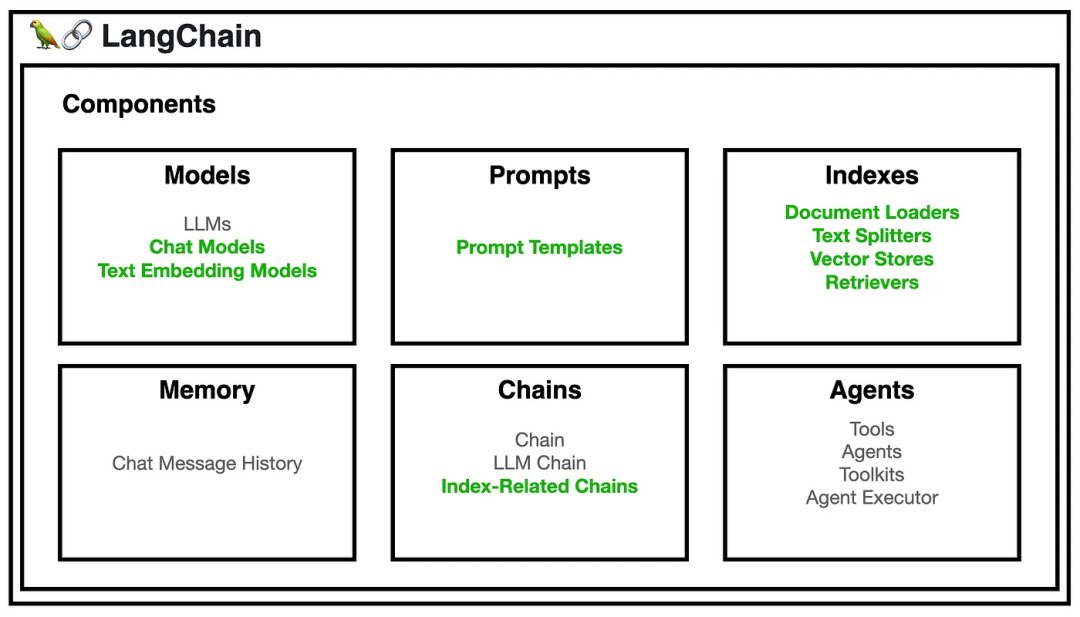
Models
One of the core values of LangChain is that it provides a standard model interface; then we can freely switch between different models, currently there are two main types of models, but considering the use of scenarios, for our general users, it is recommended to use a model that is the text generation model.
Speaking of models, we understand that the model is ChatGPT. A simple model can only generate text content.
-
Language Models
Used for text generation, text as input and output is also text.
-
Ordinary LLM: Receive text strings as input and return text strings as output.
-
Chat Model: Take a list of chat messages as input and return a chat message.
Code examples:
from langchain.schema import HumanMessage
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
llm = OpenAI()
chat_model = ChatOpenAI()
print(llm("say hi!"))
print(chat_model.predict("say hi!"))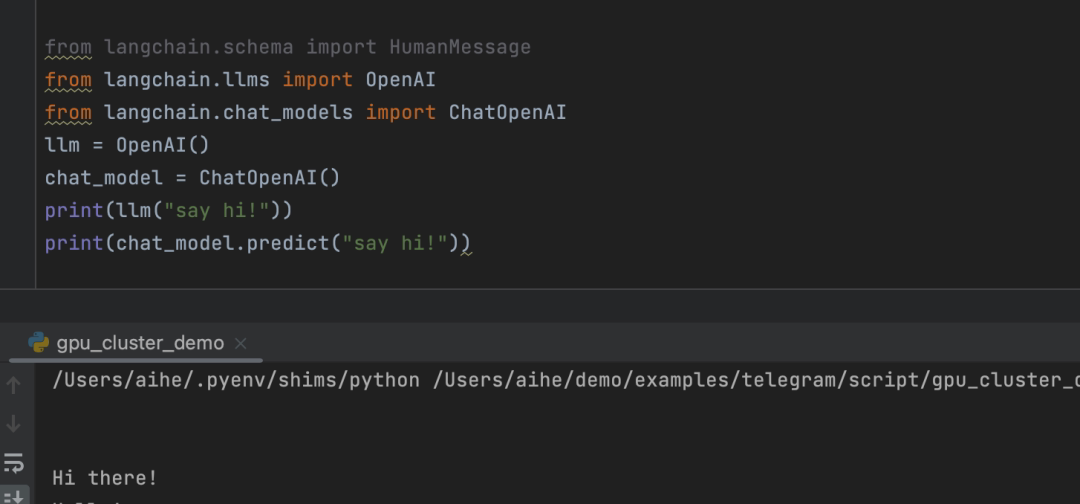
-
Text Embedding Models
Convert text to a description in floating-point form:
These models receive text as input and return a set of floating point numbers. These floating point numbers are usually used to represent the semantic information of the text, in order to carry out text similarity calculations, cluster analysis and other tasks. Text embedding models can help developers create richer connections between texts and improve the performance of applications based on large language models.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])
print(doc_result)
-
Prompts
Prompts are the way we interact with the model, or the input to the model, through which we can make the model return what we expect, such as making the model return data to us in a certain format.
LangChain provides a number of tools to make it easier for us to construct the prompters we want, and to understand that these tools make it easier for us to construct prompters. The main tools are as follows:
PromptTemplates
PromptTemplates, a language model prompt template, is a prompt template that allows us to repeatedly generate prompts and reuse our prompts. It contains a text string ("template"), takes a set of parameters from the user, and generates a prompt, including:
-
A description of the language model and what role it should play.
-
A small set of examples to help LLM generate better responses.
-
Specific questions.
Code examples:
from langchain import PromptTemplate
template = """
I want you to act as a naming consultant for new companies.
What is a good name for a company that makes {product}?
"""
prompt = PromptTemplate(
input_variables=["product"],
template=template,
)
prompt.format(product="colorful socks")
# -> I want you to act as a naming consultant for new companies.
# -> What is a good name for a company that makes colorful socks?
ChatPrompt Templates
ChatPrompt Templates: ChatModels accept a list of chat messages as input. The list usually has different prompts, and each list message usually has a role.
from langchain.prompts import (
ChatPromptTemplate,
PromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
template="You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
# get a chat completion from the formatted messages
print(chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.").to_messages())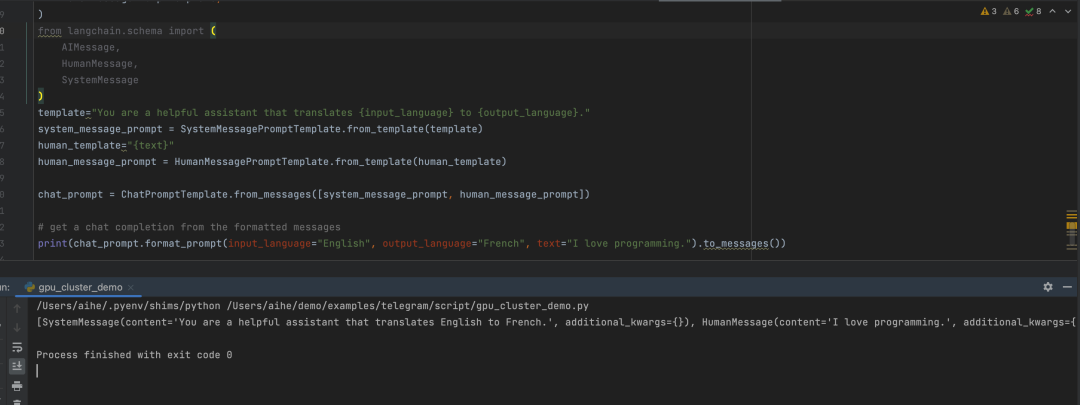
Example Selectors
Example Selectors, if you have more than one case, use ExampleSelectors to select a case for the prompt to use:
-
Customized case selector.
-
Length-based case selector: When you enter a long case, there will be fewer cases; when you enter more cases, there will be more cases.
-
Relevance selector: Select a case that is most relevant to the input.
from langchain.prompts.example_selector.base import BaseExampleSelector
from typing import Dict, List
import numpy as np
class CustomExampleSelector(BaseExampleSelector):
def __init__(self, examples: List[Dict[str, str]]):
self.examples = examples
def add_example(self, example: Dict[str, str]) -> None:
"""Add new example to store for a key."""
self.examples.append(example)
def select_examples(self, input_variables: Dict[str, str]) -> List[dict]:
"""Select which examples to use based on the inputs."""
return np.random.choice(self.examples, size=2, replace=False)
examples = [
{"foo": "1"},
{"foo": "2"},
{"foo": "3"}
]
# Initialize example selector.
example_selector = CustomExampleSelector(examples)
# Select examples
print(example_selector.select_examples({"foo": "foo"}))
# -> array([{'foo': '2'}, {'foo': '3'}], dtype=object)
# Add new example to the set of examples
example_selector.add_example({"foo": "4"})
print(example_selector.examples)
# -> [{'foo': '1'}, {'foo': '2'}, {'foo': '3'}, {'foo': '4'}]
# Select examples
print(example_selector.select_examples({"foo": "foo"}))
# -> array([{'foo': '1'}, {'foo': '4'}], dtype=object)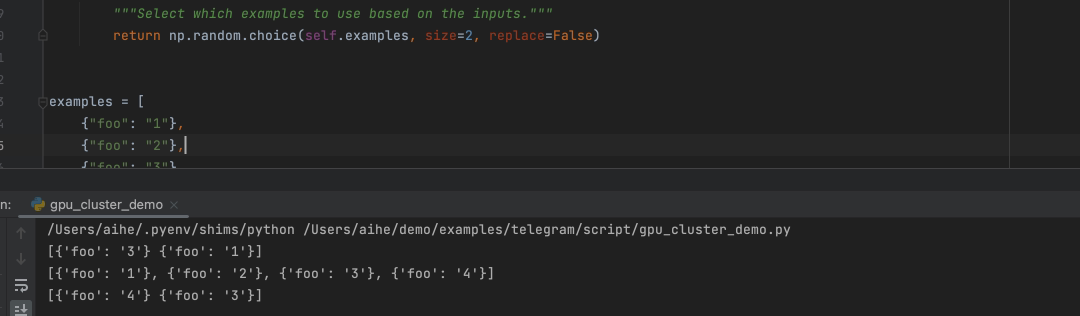
OutputParsers
The output parser, OutputParsers, allows LLM to output more structured information:
-
Indicates how the model formats the output: get_format_instructions
-
Parses the output into the desired format: parse(str)
Main Parsers:
-
CommaSeparatedListOutputParser to have LLM return in comma-separated form. ['Vanilla', 'Chocolate', 'Strawberry', 'Mint Chocolate Chip', 'Cookies and Cream'].
-
StructuredOutputParser generates structured content directly without defining objects. It is similar to PydanticOutputParser, but it doesn't need to define objects.
-
PydanticOutputParser defines an object model for LLM to follow to return data.
You can see that we have defined the Joke class, and then PydanticOutputParser allows LLM to return data to us according to the format of the object we defined.
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field, validator
from typing import List
model_name = 'text-davinci-003'
temperature = 0.0
model = OpenAI(model_name=model_name, temperature=temperature)
# Define your desired data structure.
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
# You can add custom validation logic easily with Pydantic.
@validator('setup')
def question_ends_with_question_mark(cls, field):
if field[-1] != '?':
raise ValueError("Badly formed question!")
return field
parser = PydanticOutputParser(pydantic_object=Joke)
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
joke_query = "Tell me a joke."
_input = prompt.format_prompt(query=joke_query)
output = model(_input.to_string())
print(parser.get_format_instructions())
print(output)
print(parser.parse(output))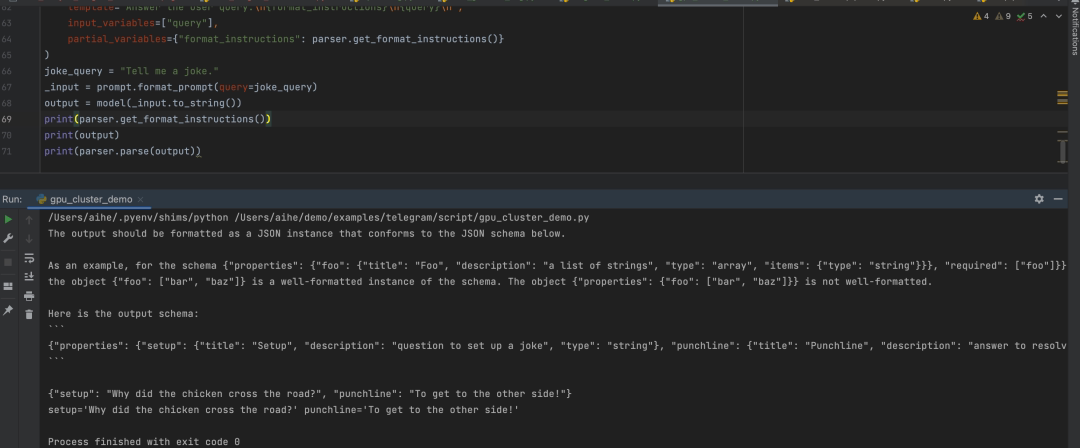
Indexes
Indexes can make the document structured, so that LLM can directly interact with the document better; for example, for Q&A, knowledge base, etc., LLM first from the document to get the answer.
LangChain also provides many useful functions and tools for indexing, which makes it easy for us to load and retrieve different document data from outside.
For data indexing, LangChain provides the main tools :
-
Document Loaders: Load documents from different data sources. When using Loader to read the data source, the data source needs to be converted to Document objects can be used subsequently.
-
Text Splitters: Realization of text segmentation, we do every time, whether the text is a prompt sent to the openai api, or still use the openai api embedding function, is a character limit. For example, we will send a 300-page PDF to the openai api, let it summarize, it will definitely report more than the maximum Token error. So here we need to use a text splitter to split the Document we loader in.
-
VectorStores: Store the document as a vector structure, because data relevance search is actually a vector operation. So, no matter we use the openai api embedding function or directly through the vector database direct query, we need to vectorize our loaded data Document in order to carry out vector search. Converting to vectors is also very simple, we just need to store the data into the corresponding vector database to complete the vector conversion.
-
Retrievers: Used to retrieve the data of the document.
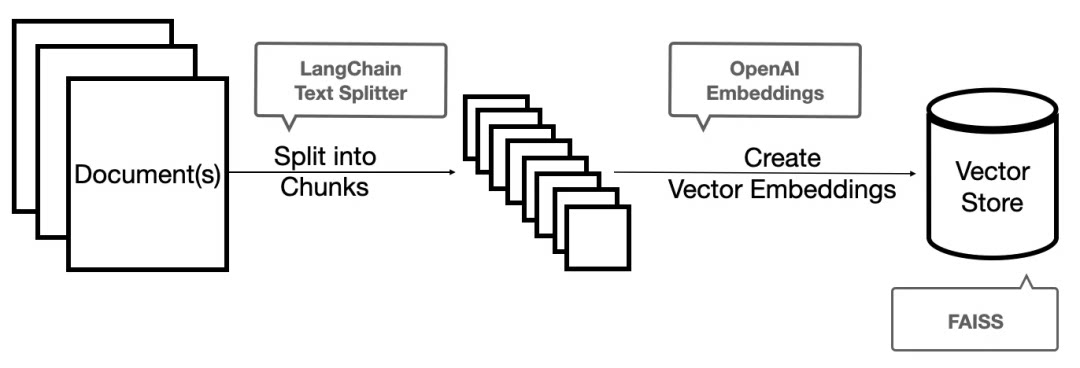
Give a case study to understand the usage of different tools:
-
Load the document.
-
Separate the document into different blocks.
-
Convert to a vector store.
-
Convert the vector store into a retriever and give it to LangChain for Q&A.
import os
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.indexes import VectorstoreIndexCreator
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.llms import OpenAI
# Set proxy
os.environ['HTTP_PROXY'] = 'socks5h://127.0.0.1:13659'
os.environ['HTTPS_PROXY'] = 'socks5h://127.0.0.1:13659'
# Create text loader
loader = TextLoader('/Users/aihe/Downloads/demo.txt', encoding='utf8')
# Load document
documents = loader.load()
# Text split
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# Calculate embedding vectors
embeddings = OpenAIEmbeddings()
# Create a vector library
db = Chroma.from_documents(texts, embeddings)
# Convert the vector library to retriever
retriever = db.as_retriever()
# Create a retrieval Q&A system
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
# Run the Q&A retrieval
query = "How to apply for a tenant?"
print(qa.run(query))
print(qa.run("Can you explain the functions you can provide?"))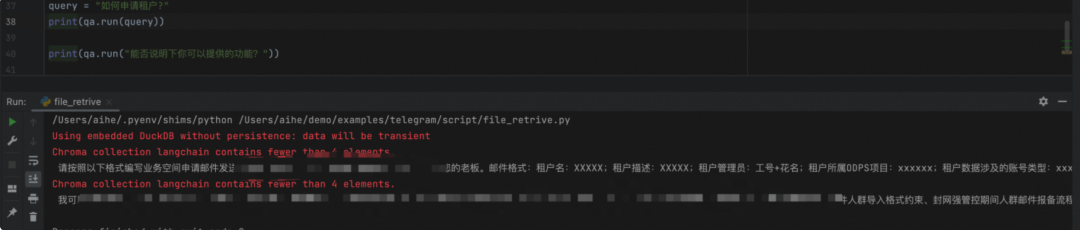
Storage (Memory)
By default, both Agent and Chain are stateless, which means that you don't know what the last conversation was about after using them. Each query is independent.
However, in some applications, it is important to remember the content of the last conversation, such as chatting. LangChain also provides some related tool classes.
from langchain import ConversationChain, OpenAI
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("Hello!")
memory.chat_memory.add_ai_message("How are you?")
llm = OpenAI(temperature=0)
chain = ConversationChain(llm=llm,
verbose=True,
memory=memory)
chain.predict(input="How are you doing lately!")
print(chain.predict(input="I feel great. I just had a conversation with AI."))
Chains
Chains allow us to combine multiple components into a single application. For example, we create a chain that accepts input from the user, then formats the user's input into a prompt via PromptTemplate, and then feeds that prompt to LLM.
We can also combine some chains together to build more complex chains.
A simple example:
# Import required modules and classes
from langchain.chains import LLMChain
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate
from langchain.prompts.chat import (
ChatPromptTemplate, # Import dialogue template class
HumanMessagePromptTemplate, # Import human message template class
)
# Create human message template class
human_message_prompt = HumanMessagePromptTemplate(
prompt=PromptTemplate(
template="Give me a good company name that makes {product}?", # Input template, where product is a placeholder
input_variables=["product"], # Specify input variable as product
)
)
# Create dialogue template class
chat_prompt_template = ChatPromptTemplate.from_messages([human_message_prompt])
# Create OpenAI chat model object
chat = ChatOpenAI(temperature=0.9)
# Create LLMChain object, pass chat model and dialogue template
chain = LLMChain(llm=chat, prompt=chat_prompt_template)
# Run LLMChain object and output the result
print(chain.run("Socks"))
Agents
Agents are using LLM as a thinking tool to decide what to do at the moment. We give the agent a set of tools, the agent determines which tools to use to accomplish the goal based on our input, and then keeps running the tools to accomplish the goal.
Agent can be seen as an enhanced version of Chain, not only binding templates, LLM, but also adding some tools to the agent.
Agent is an intelligent agent that is responsible for selecting the appropriate tool to operate among a set of available tools based on user input and application scenarios. The agent can use different strategies to decide how to perform an operation based on the complexity of the task.There are two types of Agents:
-
Action Agents: This type of Agent performs one action at a time and then decides what to do next based on the results.
-
Plan-and-Execute Agents: This type of agent first decides on a list of actions to be performed, and then performs them one at a time based on the list judged above.
For simple tasks, action agents are more common and easier to implement. For more complex or long-running tasks, the initial planning step of Plan-Execute Agents helps to maintain long-term goals and keep focus. However, this comes at the cost of more calls and higher latency. The two Agents are not mutually exclusive, and it is possible to make the Action Agent responsible for executing the Plan-Execute Agent's plans.
The core concepts involved in Agent are as follows:
-
Agent: This is the main logic of the application. The Agent exposes an interface that accepts user input and a list of actions that the Agent has performed, and returns AgentAction or AgentFinish.
-
Tools: These are the actions that the agent can take. For example, initiating HTTP requests, sending emails, and executing commands.
-
Toolkits: These are a set of tools designed for a specific use case. For example, in order for an agent to interact with a SQL database in an optimal way, it may need a tool to execute queries and another to view tables. It can be seen as a collection of tools.
-
Agent Executor: This wraps the agent with a set of tools. It is responsible for running the agent iteratively until the stop condition is met.
A case:
# Import required modules and classes
from langchain.agents import load_tools # Import loading tool function
from langchain.agents import initialize_agent # Import initialization agent function
from langchain.agents import AgentType # Import agent type class
from langchain.llms import OpenAI # Import OpenAI language model class
import os # Import os module
# Create OpenAI language model object, set temperature to 0, that is, turn off randomness
llm = OpenAI(temperature=0)
# Load required tools, including serpapi and llm-math
tools = load_tools(["serpapi", "llm-math"], llm=llm)
# Initialize agent object, set agent type to ZERO_SHOT_REACT_DESCRIPTION, output detailed information
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
# Run the agent object and ask it the result of Trump's age and his age divided by 2
agent.run("How old is Trump this year? What is his age divided by 2?")
Agent Initialization Type
The above code has an initialization phase for Agent, agent = AgentType.ZERO_SHOT_REACT_DESCRIPTION, the agent type determines how the agent will use the tools, process inputs, and interact with the user. Thus, it provides a targeted service to the user. Among the types that can be selected are the following:
-
ZERO_SHOT_REACT_DESCRIPTION: This agent uses the ReAct framework to determine which tool to use based solely on the tool's description, and can provide any number of tools. A description is required for each tool.
-
react-docstore: This agent uses the ReAct framework to interact with a document store (docstore). Two tools must be provided: a search tool and a lookup tool (they must be named exactly Search and Lookup). The Search tool should be used to search for documents, and the Lookup tool should look up terms in recently found documents. This proxy is equivalent to the original ReAct paper, especially the Wikipedia example.
-
self-ask-with-search: This agent uses a single tool called Intermediate Answer. This tool should be able to look up factual answers to questions. This agent is equivalent to the original self-ask-with-search paper, which provided the Google Search API as a tool.
-
conversational-react-description: This agent is intended to be used in conversation settings. The prompts make the agent helpful in conversations. It uses the ReAct framework to decide which tool to use and uses memory to remember previous conversational interactions.
-
structured-chat-zero-shot-react-description: Any tool can be used in the conversation, and the context of the conversation can be remembered.
Tools
There are a number of tools available by default, such as Gmail, database queries, JSON processing, etc. There are also lists of individual tools, which can be found in the documentation:
https://python.langchain.com/en/latest/modules/agents/tools/getting_started.html
We use a custom tool to understand how to use the tool, because when we use LangChain later, we will continue to customize the tool.
When writing a tool, you need to prepare:
-
Name.
-
Tool description: Explain what your tool does.
-
Parameter structure: What is the structure of the input parameters required by the current tool?
LangChain Use Case
Suppose we need to build an LLM-based Q&A system that needs to extract information from a specified data source to answer a user's question. We can use the data enhancement generation function in LangChain to interact with external data sources to obtain the required data. Then, input the data into the LLM to generate the answer. The memory feature can help us maintain the relevant state between multiple calls, thus improving the performance of the Q&A system. In addition, we can use the intelligent agent function to achieve automatic optimization of the system. Finally, with the evaluation hints and chain implementation provided by LangChain, we can evaluate and optimize the performance of the Q&A system.
LangChain for Images
A language model based text to generate images tool is implemented, calling different tool functions to finally generate images. The following tools are mainly provided:
-
random_poem: randomly return Chinese poems.
-
prompt_generate: generates English prompts based on Chinese prompts.
-
generate_image: generate the corresponding image according to the English prompt.
import base64
import json
import os
from io import BytesIO
import requests
from PIL import Image
from pydantic import BaseModel, Field
from langchain.agents import AgentType, initialize_agent, load_tools
from langchain.chat_models import ChatOpenAI
from langchain.llms import OpenAI
from langchain.tools import BaseTool, StructuredTool, Tool, tool
from langchain import LLMMathChain, SerpAPIWrapper
def generate_image(prompt: str) -> str:
"""
Generate the corresponding image according to the prompt
Args:
prompt (str): English prompt
Returns:
str: The path of the image
"""
url = "http://127.0.0.1:7860/sdapi/v1/txt2img"
headers = {
"accept": "application/json",
"Content-Type": "application/json"
}
data = {
"prompt": prompt,
"negative_prompt": "(worst quality:2), (low quality:2),disfigured, ugly, old, wrong finger",
"steps": 20,
"sampler_index": "Euler a",
"sd_model_checkpoint": "cheeseDaddys_35.safetensors [98084dd1db]",
# "sd_model_checkpoint": "anything-v3-fp16-pruned.safetensors [d1facd9a2b]",
"batch_size": 1,
"restore_faces": True
}
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
response_data = response.json()
images = response_data['images']
for index, image_data in enumerate(images):
img_data = base64.b64decode(image_data)
img = Image.open(BytesIO(img_data))
file_name = f"image_{index}.png"
file_path = os.path.join(os.getcwd(), file_name)
img.save(file_path)
print(f"Generated image saved at {file_path}")
return file_path
else:
print(f"Request failed with status code {response.status_code}")
def random_poem(arg: str) -> str:
"""
Randomly return Chinese poems
Returns:
str: random Chinese poems
"""
llm = OpenAI(temperature=0.9)
text = """
Can you help me randomly select a poem from the Chinese poetry database for me, I hope it is a poem with scenery and pictures:
For example: Mountains and rivers are so dense that there seems to be no way out, but when you look up, you will find another village.
"""
return llm(text)
def prompt_generate(idea: str) -> str:
"""
English prompts are required to generate pictures
Args:
idea (str): Chinese prompts
Returns:
str: English prompts
"""
llm = OpenAI(temperature=0, max_tokens=2048)
res = llm(f"""
Stable Diffusion is an AI art generation model similar to DALLE-2.
Below is a list of prompts that can be used to generate images with Stable Diffusion:
- portait of a homer simpson archer shooting arrow at forest monster, front game card, drark, marvel comics, dark, intricate, highly detailed, smooth, artstation, digital illustration by ruan jia and mandy jurgens and artgerm and wayne barlowe and greg rutkowski and zdislav beksinski
- pirate, concept art, deep focus, fantasy, intricate, highly detailed, digital painting, artstation, matte, sharp focus, illustration, art by magali villeneuve, chippy, ryan yee, rk post, clint cearley, daniel ljunggren, zoltan boros, gabor szikszai, howard lyon, steve argyle, winona nelson
- ghost inside a hunted room, art by lois van baarle and loish and ross tran and rossdraws and sam yang and samdoesarts and artgerm, digital art, highly detailed, intricate, sharp focus, Trending on Artstation HQ, deviantart, unreal engine 5, 4K UHD image
- red dead redemption 2, cinematic view, epic sky, detailed, concept art, low angle, high detail, warm lighting, volumetric, godrays, vivid, beautiful, trending on artstation, by jordan grimmer, huge scene, grass, art greg rutkowski
- a fantasy style portrait painting of rachel lane / alison brie hybrid in the style of francois boucher oil painting unreal 5 daz. rpg portrait, extremely detailed artgerm greg rutkowski alphonse mucha greg hildebrandt tim hildebrandt
- athena, greek goddess, claudia black, art by artgerm and greg rutkowski and magali villeneuve, bronze greek armor, owl crown, d & d, fantasy, intricate, portrait, highly detailed, headshot, digital painting, trending on artstation, concept art, sharp focus, illustration
- closeup portrait shot of a large strong female biomechanic woman in a scenic scifi environment, intricate, elegant, highly detailed, centered, digital painting, artstation, concept art, smooth, sharp focus, warframe, illustration, thomas kinkade, tomasz alen kopera, peter mohrbacher, donato giancola, leyendecker, boris vallejo
- ultra realistic illustration of steve urkle as the hulk, intricate, elegant, highly detailed, digital painting, artstation, concept art, smooth, sharp focus, illustration, art by artgerm and greg rutkowski and alphonse mucha
I want you to write me a list of detailed prompts exactly about the idea written after IDEA. Follow the structure of the example prompts. This means a very short description of the scene, followed by modifiers divided by commas to alter the mood, style, lighting, and more.
IDEA: {idea}""")
return res
class PromptGenerateInput(BaseModel):
"""
Input model classes required to generate English prompts
"""
idea: str = Field()
class GenerateImageInput(BaseModel):
"""
Input model class required to generate images
"""
prompt: str = Field(description="English prompt")
tools = [
Tool.from_function(
func=random_poem,
name="Poetry acquisition",
description="Randomly return Chinese poems"
),
Tool.from_function(
func=prompt_generate,
name="prompt generation",
description="Generate English prompts corresponding to the image. The current tool can convert the input into English prompts for easy generation",
args_schema=PromptGenerateInput
),
Tool.from_function(
func=generate_image,
name="Image generation",
description="Generate the corresponding image according to the prompts. The prompts need to be in English, and the return is the path of the image",
args_schema=GenerateImageInput
),
]
def main():
"""
Main function, initialize the agent and execute the dialogue
"""
llm = OpenAI(temperature=0)
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("Help me generate a picture of a poem?")
if __name__ == '__main__':
main()

LangChain for Q&A
Refer to the index section above:
import os
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.indexes import VectorstoreIndexCreator
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.llms import OpenAI
# Set proxy
os.environ['HTTP_PROXY'] = 'socks5h://127.0.0.1:13659'
os.environ['HTTPS_PROXY'] = 'socks5h://127.0.0.1:13659'
# Create text loader
loader = TextLoader('/Users/aihe/Downloads/demo.txt', encoding='utf8')
# Load document
documents = loader.load()
# Text split
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# Calculate embedding vectors
embeddings = OpenAIEmbeddings()
# Create a vector library
db = Chroma.from_documents(texts, embeddings)
# Convert the vector library to retriever
retriever = db.as_retriever()
# Create a retrieval Q&A system
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
# Run the Q&A retrieval
query = "How to apply for a tenant?"
print(qa.run(query))
print(qa.run("Can you explain the functions you can provide?"))
Langchain outputs structured JSON data
Referring to the above concepts, the cue word tool provides an OutputParser that can convert our object into a cue word that tells LLM what structure to return.
import requests
from langchain.agents import AgentType, initialize_agent
from langchain.chat_models import ChatOpenAI
from langchain.tools import StructuredTool
from pydantic import BaseModel, Field
def post_message(type: str, param: dict) -> str:
"""
When you need to generate crowds, analyze portraits, and ask questions, use the following instructions: url is fixed to: http://localhost:3001/
If the request is to generate crowds, the type of the request is crowd; if the request is to analyze portraits, the type of the request is analyze; if it is other or Q&A, the type of the request is question;
The param of the request body can pass in the user-specified conditions
"""
result = requests.post("http://localhost:3001/", json={"type": type, "param": param})
return f"Status: {result.status_code} - {result.text}"
class PostInput(BaseModel):
# body: dict = Field(description="""Format:{"type":"","param":{}}""")
type: str = Field(description="Request type, crowd is crowd, portrait is analyze")
param: dict = Field(description="Detailed description of the request")
llm = ChatOpenAI(temperature=0)
tools = [
StructuredTool.from_function(post_message)
]
agent = initialize_agent(tools, llm, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("I want to generate a group of people who are male and have visited Taote in 180 days?")
LangChain for Your Own Chatbot
Originally do chatbot, need some front-end code, but there have been corresponding open source tools to help us LangChian various components to do the visualization, direct drag and drop can be, we directly use LangFlow;
pip install langflowAnd then run the command:
langfowIf there is a conflict with the local LangChain, you can run langfow using Docker:
FROM python:3.10-slim
RUN apt-get update && apt-get install gcc g++ git make -y
RUN useradd -m -u 1000 user
USER user
ENV HOME=/home/user \
PATH=/home/user/.local/bin:$PATH
WORKDIR $HOME/app
COPY --chown=user . $HOME/app
RUN pip install langflow>==0.0.71 -U --user
CMD ["langflow", "--host", "0.0.0.0", "--port", "7860"]
Configure the three components of LangChain in the interface: in the bottom right corner is the corresponding chat window, enter the OpenAI key.
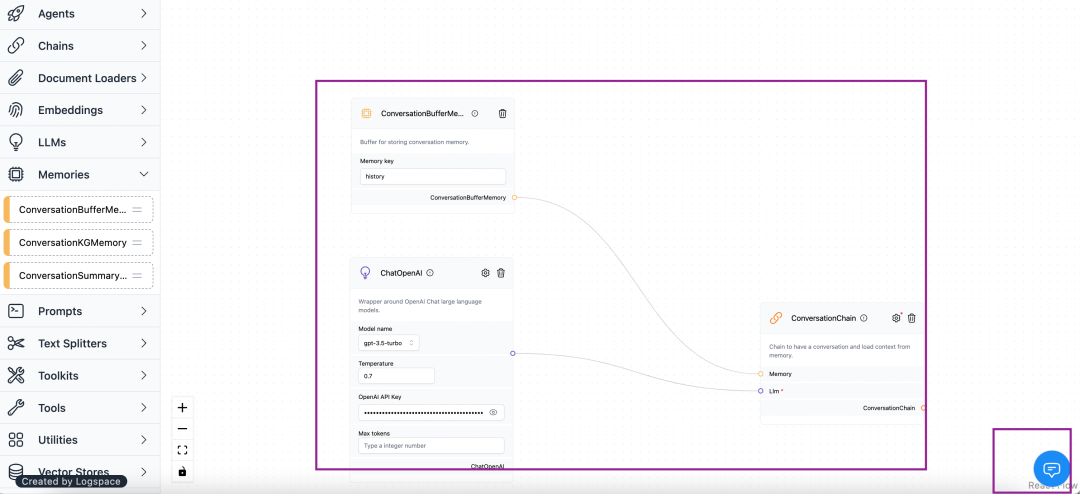
Basically, you don’t need to write any code in the whole process. You just need to understand what the LangChain components do, and you can basically build a simple chatbot.
Other LangChain components, such as proxy, memory, and data index, can also be used.
LangChain's Future Prospects
LangChain provides a powerful framework for building applications based on large-scale language models, which will be gradually applied to various fields, such as intelligent customer service, text generation, knowledge graph construction, and so on. As more tools and resources are integrated with LangChain, the large language model will have a greater increase in human productivity.
Application Scenario Conceptualization:
-
Intelligent Customer Service: Combine a chat model, an autonomous intelligent agent, and a Q&A function to develop an intelligent customer service system to help users solve problems and improve customer satisfaction.
-
Personalized Recommendation: Use intelligent agents and text embedding models to analyze users' interests and behaviors, and provide personalized content recommendations for users.
-
Knowledge Graph Construction: Automatically extract knowledge from documents and construct knowledge graphs by combining Q&A, text summarization, and entity extraction functions.
-
Automatic Digest and Key Information Extraction: Utilize LangChain's text summarization and extraction features to extract key information from a large amount of text to generate concise and easy-to-understand summaries.
-
Code Review Assistant: Analyze code quality and provide developers with automated code review suggestions through code understanding and intelligent agent functions.
-
Search Engine Optimization: Combine a text embedding model and an intelligent agent to analyze the relevance of webpage content to user queries and improve search engine ranking.
-
Data Analysis and Visualization: Through interaction with APIs and query form data functions, automatically analyze data and generate visualization reports to help users understand the insightful information in the data.
-
Intelligent Programming Assistant: Combining code understanding and intelligent agent functions, it automatically generates code snippets based on user-input requirements to improve developers' work efficiency.
-
Online Education Platform: Utilizing Q&A and chat modeling features, it provides real-time academic support to students to help them solve problems encountered in their studies.
-
Automation testing: Combine intelligent agent and agent simulation functions to develop automated test scenarios and improve the efficiency and coverage of software testing.
Summary
This paper introduced the LangChain framework, which is capable of combining large language models with other computational or knowledge sources to enable more powerful applications. Then, the key concepts of LangChain were explained in detail, and some case studies based on the framework were attempted, aiming to help readers understand how LangChain works more easily.
Looking ahead, LangChain is expected to play a great role in various fields and facilitate the change of our work efficiency. We are on the eve of the AI explosion, and actively embracing the new technology will bring a completely different feeling.
Reference:
-
Langchain Chinese primer: https://github.com/liaokongVFX/LangChain-Chinese-Getting-Started-Guide
-
LangChain official document: https://python.langchain.com/en/latest/modules/indexes/getting_started.html
-
LangFlow, a visual orchestration tool for LangChain: https://github.com/logspace-ai/langflow